
FAIR Principles | What Are They And Why Are They Important?
Updated June 7th, 2022
Information is everything in our current society. And as we are surrounded by more data by the minute, the growth of new information increases exponentially. This growth is crucial in advancing technology, science, research, and other fields.
However, inaccurate information sharing can greatly harm the scientific community. Thankfully, the reuse of scholarly data has been improved thanks to the creation of a measurable set of principles. This is where FAIR principles play a vital role. Their main objective is to guarantee the validity and reproducibility of the published data.
FAIR Principles were first published in the Scientific Data journal in 2016. They were also included in the European Horizon 2020 program as a requirement for the data published.
You’ll learn all about the FAIR Principles, their importance, and how to check the fairness of your data in this article.
What Are FAIR Principles?
FAIR is an acronym that defines the following principles:
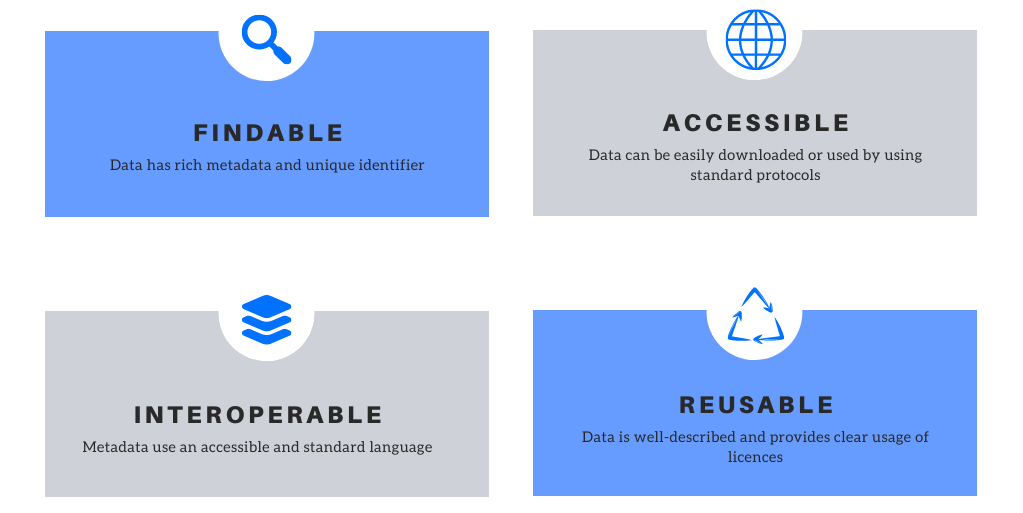
FINDABLE: To support findability, citation, and reuse, it’s important to have rich metadata. The more complete the metadata, the more accurate the interpretation of the information will be, as the context of the data will be clearer. Persistent (unique) identifiers are also necessary because they identify your data and facilitate citation.
ACCESSIBLE: Not all data has to be open. However, if it is accessible, data should be downloadable without requiring special protocols.
As open as possible, as closed as necessary
INTEROPERABLE: Data should be integrable with other applications. Therefore, it’s important to use common formats, a standard language, controlled vocabulary, keywords, etc.
REUSABLE: Make your information comprehensible by creating documentation. Documentation should help interpret the information correctly by explaining the document content, the steps followed in processing the data, and adding extra information needed. It also requires a transparent license and an explanation of how the data was formed.
FAIR Data Importance
One of the most significant challenges of science is facilitating learning for both humans and machines. Thanks to the FAIR principles, we can generate data following the Open Access philosophy. Additionally, by following this set of guidelines when generating content, we establish a common basis that increases the amazing potential of Open Access.
Check The "FAIRness" of Your Data With Orvium
An exciting tool that allows you to see how “FAIR” your data is the FAIR self-assessment tool, developed by the Australian Research Data Commons. After completing a series of questions, you’ll get a score that determines the “FAIRness” of the data.
On our Orvium platform, we encourage publishers to apply FAIR Principles to their publications by providing the following features:
- Set a DOI (Digital Object Identifier) to a publication to make it findable even if the URL changes. Authors can also use an ORCID iD to identify themselves.
- All publications are accessible to everyone and there is no need for special protocols to download and obtain the data.
- We make use of the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), that makes the data accessible to humans and machines. It’s also a tool that allows metadata interoperability and integration between different repositories. For example, we expose our metadata to integrate it with the OpenAIRE infrastructure.
- Thanks to OAI-PMH, the metadata of the publications available in Orvium follows a Dublin Core format, one of the most used metadata standards to guarantee its interoperability. All the data has Creative Commons license rights attached to clearly establish the way that information can be reused.
Our aim is to build a big community based on Open Access and these guidelines ensure a common structure, making the data useful to the scientific community. To learn more about how we comply with the FAIR principles, check out our platform.

